In der Welt der großen Sprachmodelle (Large Language Models, LLMs) wie GPT gibt es eine Reihe von faszinierenden Herausforderungen, die auf den ersten Blick nicht sofort ersichtlich sind. Eines dieser Probleme, das inzwischen als das “Strawberry”-Problem bekannt ist, zeigt, wie die Art und Weise, wie diese Modelle Text verarbeiten, zu unerwarteten Ergebnissen führen kann. So zählt GPT im Wort Strawberry lediglich 2 R, was im Internet zu viel Schadenfreude geführt hat. Dieses Verhalten ist auf die Art und Weise zurückzuführen, wie LLMs Text verarbeiten.
Das Problem erklärt

Betrachten wir das Wort “Strawberry”. Auf den ersten Blick scheint es einfach zu sein – ein alltägliches Wort ohne offensichtliche Komplexität. Doch wenn wir tiefer in die Art und Weise eintauchen, wie ein LLM dieses Wort verarbeitet, stoßen wir auf ein interessantes Phänomen.
Wenn das LLM damit beauftragt wird, die Anzahl der Vorkommen eines bestimmten Buchstabens, beispielsweise “R”, im Wort “Strawberry” zu ermitteln zählt es lediglich zwei R. Obwohl “Strawberry” drei “R” enthält. Warum passiert das?
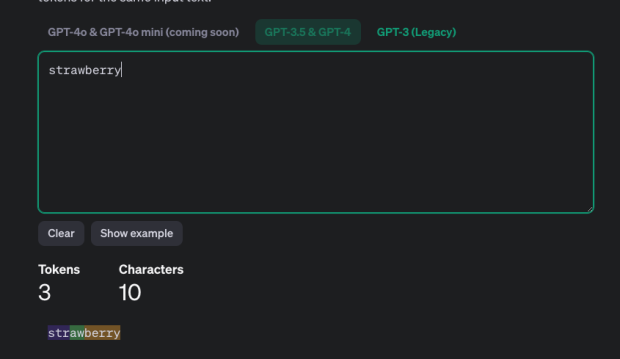
Der Kern dieses Problems liegt in der Tokenisierung. Die Tokenisierung ist der Prozess, bei dem ein Modell Text in kleinere Einheiten, sogenannte “Tokens”, aufteilt, die es dann zur Verarbeitung verwendet. Im Fall von “Strawberry” teilt die GPT-Tokenisierung das Wort in drei Tokens auf: “STR”, “AW” und “BERRY”.
Wenn das Modell nun die “R” zählen soll, erkennt es, dass “STR” und “BERRY” jeweils “R” enthalten. Das Modell erkennt diese Buchstaben aufgrund der Tokenisierung, berücksichtigt jedoch nicht, dass ‘BERRY’ zwei ‘R’ enthält. Daher kommt das Modell fälschlicherweise zu dem Schluss, dass es nur zwei “R” gibt.
Ein Vergleich: Die Farbenblindheit-Analogie
Um dies besser zu verstehen, stellen Sie sich vor, Sie bitten eine farbenblinde Person, in einem Bild Rot und Grün zu identifizieren. Die Person könnte eine der Farben übersehen oder die beiden verwechseln, nicht aufgrund eines Mangels an Intelligenz oder Anstrengung, sondern weil ihre Wahrnehmung von Natur aus eingeschränkt ist. Ähnlich verhält es sich mit dem LLM, das sich der vollständigen Struktur des Wortes nach der Tokenisierung nicht mehr vollständig bewusst ist.
Im “Strawberry”-Problem ist das Modell sozusagen “farbenblind” für die gesamte Struktur des Wortes, da es nur die Tokens sieht und nicht das gesamte Wort in seiner ungebrochenen Form. Es ist, als hätte das Modell ein unvollständiges Verständnis, was zu einer unvollständigen Antwort führt.
Ein interessanter Kontrast: Buchstaben in einer Liste zählen
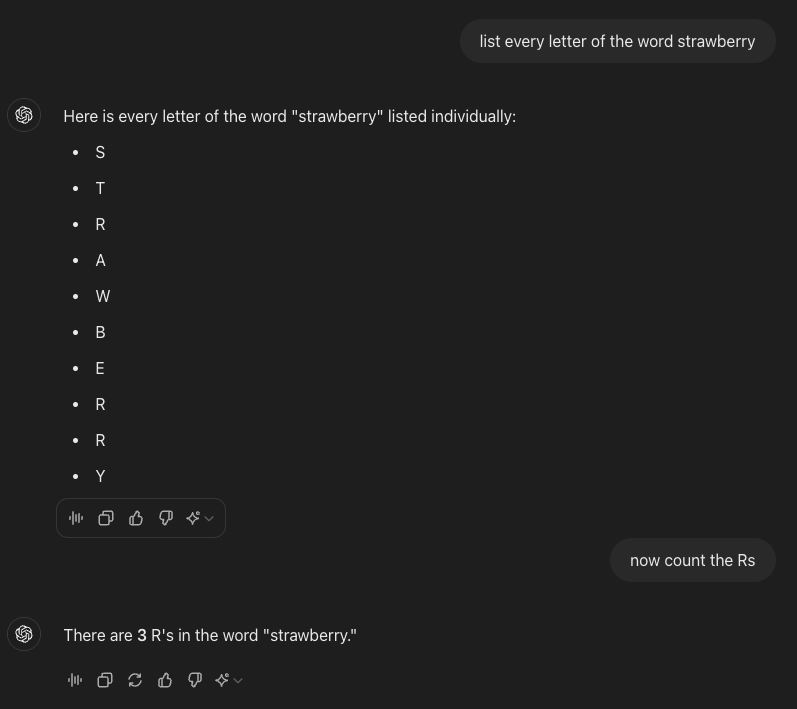
Interessanterweise wird das LLM korrekt antworten, wenn man es auffordert, jeden Buchstaben des Wortes “Strawberry” einzeln aufzulisten und dann zu zählen. Da jeder Buchstabe in einer Liste sein eigenes Token erhält, kann das Modell die Anzahl der “R” korrekt bestimmen. Dies zeigt, dass die Tokenisierung im Zusammenhang mit der Aufgabenstellung eine entscheidende Rolle spielt. Interessanterweise ist GPT in der Lage, das Wort korrekt zu buchstabieren, wenn man es auffordert, jeden Buchstaben einzeln aufzulisten.
Implikationen und Überlegungen
Dieses Problem verdeutlicht eine breitere Herausforderung im Design und in der Anwendung von LLMs. Während diese Modelle bemerkenswerte Erfolge in verschiedenen Aufgaben erzielt haben, kann ihre Abhängigkeit von der Tokenisierung zu nuancierten Fehlern führen, insbesondere bei Aufgaben, die präzise Detailarbeit erfordern. Buchstaben analysieren, Mathematik und Zählen sind keine Aufgaben, für die LLMs gemacht wurden. Auch beim Raten von Wörtern im Spiel Hangman passieren diese Fehler – erwartungsgemäß – regelmäßig.
Für Entwickler und Nutzer von LLMs dient das “Strawberry”-Problem als Erinnerung daran, die inhärenten Einschränkungen dieser Modelle zu berücksichtigen. Ein Verständnis dafür, wie die Tokenisierung die Verarbeitung des Modells beeinflusst, kann helfen, Fehler zu minimieren und die Genauigkeit der ausgeführten Aufgaben zu verbessern.
Fazit
Das “Strawberry”-Problem zeigt einen subtilen, aber wichtigen Aspekt davon, wie große Sprachmodelle Text verarbeiten und verstehen. Durch das Erkennen und die Bewältigung dieser Herausforderungen können wir diese leistungsstarken Werkzeuge weiter verfeinern und die Grenzen dessen, was sie leisten können, erweitern, während wir uns ihrer aktuellen Grenzen bewusst bleiben.
Wie man von einem Farbenblinden nicht erwarten würde, unreife Erdbeeren zuverlässig von reifen zu unterscheiden, sollten wir uns bewusst sein, dass LLMs bei bestimmten Aufgaben ihre Grenzen haben.