Dieses Buch ist beim Zubettbringen meiner Tochter entstanden. Im dunklen Kinderzimmer, beim Kopfrechnen gegen das Einschlafen, stellte sich eine Frage, die so einfach klingt, dass sie eigentlich längst jemand gestellt haben müsste: In jedem Zahlensystem trägt die Stelle mit dem meisten Spielraum das meiste Gewicht. Was, wenn man genau das umkehrt — wenn ausgerechnet die engste Stelle am schwersten wiegt?
Die Antwort erzwingt eine kleine, eigensinnige Welt: Zahlenräume, die endlich sind. Führende Nullen, die plötzlich den Wert verändern. Zahlen, die drei Identitäten zugleich tragen — einen Wert, eine Gestalt, einen Bruch — und ein bewiesener Satz, der besagt: Man kann nicht in zwei dieser Identitäten gleichzeitig rechnen. Konsistenz hat einen Preis.
Das Buch entwickelt diese Theorie ehrlich — mit Definitionen und Beweisen, aber auch mit allen neun Sackgassen, in die wir unterwegs gelaufen sind. Nach jedem technischen Kapitel führt ein formelfreier Rückkehrpunkt an die Oberfläche: Wer nur diese Passagen liest, versteht trotzdem, worum es geht. Am Ende steht eine präzise Landkarte — die Bewohner der Horimetrik sind wohlbekannte Objekte der Kombinatorik, aber die Operationen auf ihnen und die Sätze darüber sind neu, darunter neun Zählfolgen, die bislang in keiner Datenbank standen.
Geschrieben habe ich es nicht allein: Die Mathematik entstand in enger Zusammenarbeit mit Claude (Anthropic), Ideen steuerte GPT (OpenAI) bei. Auch davon erzählt dieses Buch — es ist nebenbei ein Werkstattbericht darüber, wie Forschung mit KI heute aussehen kann.
Gerade laufen die KI-SaaS-Wars an, und wer sie nur als neue Runde im üblichen Werkzeugrennen zwischen Claude Code, Codex und dem nächsten glänzenden Agenten missversteht, schaut auf die Oberfläche und verpasst die tektonische Verschiebung darunter. Denn es geht nicht primär darum, dass Maschinen inzwischen erstaunlich gut Code erzeugen können. Das ist nur das sichtbare Symptom. Der eigentliche Umbruch liegt tiefer, nämlich dort, wo bisher der Preis vieler Softwareprodukte stillschweigend durch Knappheit gestützt wurde, durch die Knappheit an Entwicklungszeit, an Umsetzungskapazität, an mühseliger Fleißarbeit und an Teams, die bekannte Muster zuverlässig in laufende Systeme übersetzen konnten. Genau diese Knappheit beginnt gerade zu verdampfen. Reuters beschreibt bereits sichtbar, dass KI traditionelle Softwaremodelle unter Druck setzt, besonders dort, wo Wachstum sinkt und seat-based pricing an Überzeugungskraft verliert.
Deshalb verschwindet auch nicht der Beruf des Softwareentwicklers, jedenfalls nicht für Menschen, die mehr können als Syntax an die Wand werfen. Was verschwindet, ist die bequeme Illusion, dass das bloße Herstellen von Software bereits ein belastbarer ökonomischer Burggraben sei. Wer diesen Unterschied nicht erkennt, wird in den kommenden Jahren sehr viel Marktwert verlieren und sich anschließend einreden, das Problem sei “die KI” gewesen. In Wahrheit war das Problem früher da, es wurde nur freundlich von teurer Implementierung kaschiert. Viele Produkte waren nämlich nie besonders tief, sie waren nur teuer genug im Bau, um wie Substanz zu wirken.
Genau deshalb halte ich die entscheidende Frage unserer Zeit nicht für “Kann KI Software bauen?”, sondern für etwas deutlich Unangenehmeres, nämlich: “Was an dieser Software ist noch wertvoll, wenn Code keine Knappheit mehr ist?” Und diese Frage ist brutal, weil sie den ganzen dekorativen Nebel aus Produktmarketing, Pitch-Folien und “AI-powered”-Buttonlack einfach wegwischt. Übrig bleibt dann oft erstaunlich wenig. Ein Rollenmodell, ein Dashboard, ein paar APIs, etwas Workflow, ein bisschen Suchfunktion, eine Handvoll Tabellen, darüber ein freundlicher Login, und plötzlich soll das ein unersetzbares SaaS-Produkt sein. Früher konnte man so etwas teuer verkaufen, weil der Bau langsam war. Heute muss man erklären, warum es mehr ist als ordentlich zusammengesteckte Commodity.
Das ist der Punkt, an dem Intellectual Property anfängt, wirklich wichtig zu werden. Nicht als juristische Floskel, nicht als PowerPoint-Wort mit Patentglanz, sondern als reale ökonomische Verteidigung. Echte IP liegt nicht darin, dass ein Team bekannte Standardmuster korrekt implementiert hat. Echte IP liegt dort, wo Nachbau trotz günstiger Implementierung schwierig bleibt, also in Domänenwissen, in tief verankerten Datenflüssen, in Integrationen, die an reale Prozesse angeschlossen sind, in regulatorischer Sicherheit, in Erfahrungswissen aus Randfällen, in Betriebsstabilität, in Vertrauen, in Haftung, in einem Systemverständnis, das nicht aus ein paar kopierten Tickets und einem Modellzugang entsteht. Andreessen Horowitz formuliert diese Marktverschiebung inzwischen bemerkenswert offen: “Every feature that can be built will be built.” Genau deshalb reicht Feature-Besitz als Schutz nicht mehr aus.
Anders gesagt, die Welt trennt sich gerade in zwei Klassen von Software. Auf der einen Seite steht echte Substanz, also Software, deren Wert über den Code hinausgeht und die auch dann schwer kopierbar bleibt, wenn Implementierung plötzlich billig geworden ist. Auf der anderen Seite steht Commodity Software, also das, was man erhält, wenn bekannte Patterns mit genügend Fleiß und hinreichend sauberer Technik in ein Produkt gegossen werden und anschließend so bepreist werden, als hätte man den Aggregatzustand der Informatik verändert. Genau diese zweite Klasse bekommt jetzt Probleme. Nicht weil sie niemand bauen könnte, sondern weil sie plötzlich sehr viele bauen könnten.
In den USA sieht man die Risse bereits. Das Interessante daran ist nicht einmal, dass einzelne Firmen scheitern, Firmen scheitern immer, das wirklich Relevante ist, warum sie scheitern und welche Nervosität dabei im Markt sichtbar wird. Reuters berichtet bereits über deutliche Verwerfungen an Software-Aktien, nachdem neue KI-Funktionen die Sorge verstärkt haben, dass bisher stabile Software- und Informationsmodelle von unten heraus angegriffen werden. Bloomberg berichtete 2025 über die Insolvenz von Builder.ai, einem hoch bewerteten Unternehmen, das sehr deutlich zeigt, wie schnell ein großes Narrativ kollabiert, wenn zwischen Behauptung, Substanz und belastbarer Differenzierung zu wenig echte Tragfähigkeit liegt. Das ist nicht der einzige Fall und auch kein mathematischer Beweis für die ganze These, aber es ist ein ziemlich brauchbares Menetekel.
Aus genau diesem Grund habe ich MegaRepo (https://bsnsoft.de/megarepo) gebaut. Nicht, weil die Menschheit morgens aufwacht und denkt: “Endlich, noch ein Artifact Repository Manager, jetzt kann die Zivilisation weitergehen.” So romantisch muss man wirklich nicht werden. Ich habe MegaRepo gebaut, weil ich ein Exempel zeigen wollte. Ich wollte sichtbar machen, dass ein erheblicher Teil des Marktes seine Preise nicht aus echter Tiefe bezieht, sondern aus historisch gewachsener Trägheit, aus Vertriebsmaschinerie, aus Gewohnheit, aus Installationsangst und aus dem alten Reflex, dass Software eben teuer sein müsse, weil Software zu bauen teuer sei. Genau dieser Reflex ist veraltet.
MegaRepo ist für mich deshalb nicht nur ein Produkt, sondern auch ein Argument. Es ist die praktische Demonstration der These, dass Commodity Software ihren Schutz verliert, sobald die Produktionsmittel demokratisiert werden. Wer heute ein solches System in sehr kurzer Zeit bauen kann, sauber, funktionsfähig und in sinnvoller Qualität, der entwertet nicht gute Produkte, sondern schlechte Preislogiken. Das ist ein wichtiger Unterschied. Ich zerstöre damit nicht die Idee von Wert, ich zerstöre nur die bequeme Ausrede, dass Implementierungsaufwand automatisch Wert bedeute. Das war noch nie philosophisch sauber, und ökonomisch ist es jetzt endgültig nicht mehr haltbar.
Dabei hilft es aus meiner Sicht auch nicht, Claude oder ähnliche Systeme bloß als “Tool” zu beschreiben. Diese Sprache hält das Denken zu klein. Wer von einem Tool spricht, stellt sich immer noch einen Entwickler vor, der im Wesentlichen dasselbe tut wie früher, nur ein wenig schneller. Das ist nicht falsch, aber es greift zu kurz. Ich nutze Claude nicht als Tool. Ich nutze Claude eher wie ein SE-Team, und meine eigentliche Arbeit besteht nicht darin, Zeichenketten in eine Datei zu tippen, sondern darin, fachliche Anforderungen sauber zu übersetzen, Grenzen zu schneiden, Qualitätsmaßstäbe zu definieren, Architekturentscheidungen zu treffen, Risiken zu erkennen und den Unterschied zwischen einem bloß funktionierenden System und einem wertvollen System herauszuarbeiten. Genau dort liegt heute die eigentliche Leistung.
Das verändert auch den Beruf des Softwareentwicklers, aber nicht in der infantilen Weise, in der manche Untergangspropheten oder Heilsverkäufer das beschreiben. Gute Entwickler werden nicht obsolet, sie werden entlarvt. Wer nur implementieren konnte, ohne zu verstehen, wird an Relevanz verlieren. Wer hingegen Probleme strukturieren, Abhängigkeiten erkennen, Anforderungen schärfen, Systeme führen und aus vagen fachlichen Spannungen tragfähige Lösungen formen kann, wird wichtiger. Aus dem reinen Produzenten von Code wird stärker ein Dirigent technischer Wertschöpfung. Und wie bei jedem Orchester gilt auch hier, dass die bloße Existenz vieler Instrumente noch keine Musik ergibt. Manchmal ergibt sie nur Lärm, und in manchen Firmen ist sogar der Lärm noch als Transformation budgetiert.
Deshalb glaube ich auch nicht, dass SaaS verschwindet. Das wäre zu grob und am Ende auch zu bequem formuliert. SaaS bleibt dort stark, wo nicht nur Software verkauft wird, sondern Verantwortung, Integration, Betrieb, Verlässlichkeit und Ergebnisnähe. SaaS stirbt nicht, aber ein bestimmter Typ SaaS verliert gerade seine metaphysische Aura. Die Zeit, in der man Standardsoftware mit ein paar differenzierenden Adjektiven versehen und anschließend so tun konnte, als sei das allein schon ein Burggraben, geht zu Ende. Künftig wird man genauer hinschauen müssen, und das ist gesund. Wer echte Datenvorteile besitzt, echte Integrationsmacht, echtes Domänenwissen oder echte operative Exzellenz, der hat weiterhin einen Platz. Wer dagegen nur Features zusammengesetzt hat, hat im Kern keinen dauerhaften Wert geschaffen, sondern nur eine Lücke zwischen Bedarf und Umsetzungsgeschwindigkeit monetarisiert. Diese Lücke wird nun kleiner.
Man kann es noch härter sagen, und vielleicht sollte man das auch: Eine 100.000-Euro-Software, die sich in kurzer Zeit nachbauen lässt, wird den KI-SaaS-War nicht überleben, sofern ihr Wert nicht in echter IP liegt. Nicht im Quelltext, nicht im Frontend, nicht in den fünf PowerPoint-Folien des Vertriebs, sondern in etwas, das auch dann noch schwer bleibt, wenn zehn gute Leute mit einem klaren fachlichen Ziel und einem KI-gestützten Entwicklungssetup antreten. Wenn dieser Restwert nicht vorhanden ist, dann war das Produkt nie besonders tief, sondern nur historisch gut geschützt. Das ist hart, aber Härte ist manchmal nur der unangenehme Name von Klarheit.
Genau deshalb sortiert KI den Markt nicht in “Firmen, die KI einsetzen” und “Firmen, die KI nicht einsetzen”. Das wäre zu simpel. Sie sortiert in Firmen mit echter Intellectual Property und Firmen mit teurer Commodity. Die einen werden ihre Hebel massiv vergrößern, weil sie schneller bauen können, ohne ihren Kern zu verlieren. Die anderen werden feststellen, dass ihr Kern leider der Bau selbst war. Und wer als Kern nur “wir können so etwas auch entwickeln” vorweisen kann, sollte langsam unruhig werden, denn das ist kein Burggraben mehr, das ist ein Praktikumszeugnis mit Preisetikett.
Am Ende bleibt deshalb für jede Softwarefirma nur eine wirklich ehrliche Frage, und sie ist so einfach, dass man sie kaum noch marketingtauglich verpacken kann: Was bleibt von unserem Wert übrig, wenn Code billig geworden ist? Wenn die Antwort lautet “unsere Features”, wird es unerquicklich. Wenn die Antwort lautet “unsere Integration, unsere Datenflüsse, unser Domänenwissen, unsere regulatorische Sicherheit, unser Betrieb, unser Vertrauen und unsere echte IP”, dann beginnt dort der Teil des Geschäfts, den man auch in zehn Jahren noch verteidigen kann.
Und genau das ist aus meiner Sicht die eigentliche Wahrheit der KI-SaaS-Wars. Sie zerstören nicht den Wert von Software. Sie zerstören die Selbsttäuschung rund um Software, die nie mehr war als ordentlich verpackte Commodity. Das ist für manche unbequem, für den Markt insgesamt aber heilsam. Denn Commodity darf billig werden. Sie sollte billig werden. Teuer bleiben darf, was wirklich schwer ist. Und schwer ist heute eben immer seltener das Schreiben von Code, schwer ist das Schaffen von Substanz.
Ein komplettes Echtzeit-Strategiespiel. Im Browser.
Kein Framework. Kein Build-Tool. Kein npm install.
Nur eine index.html, etwas CSS und rund 3.000 Zeilen Vanilla JavaScript.
Entwickelt im Dialog mit Claude Code. Und das Ergebnis überrascht selbst.
Die Inspiration
Die Idee war eine Mischung aus Age of Empires II, The Settlers und einem Hauch Civilization VI. Nicht als Kopie, sondern als Essenz.
Die wirtschaftliche Tiefe von The Settlers. Das militärische Tempo von Age of Empires. Die strategische Perspektive eines Civilization.
Reduziert auf das Wesentliche und umgesetzt als Single-Page-App.
Was technisch drin steckt
Das Spiel generiert eine Hex-Grid-Karte prozedural. Wälder, Seen, Goldadern, Steinbrüche, Wüsten. Jede Partie beginnt anders.
Es gibt sechs Zeitalter, von der Stammeszeit bis zur Kaiserzeit. Fortschritt ist nicht nur optisch, sondern verändert Wirtschaft, Militär und Spieltempo.
Das Wirtschaftssystem basiert auf echten Transportwegen. Holzfäller schlagen Bäume, Bauern bestellen Felder, Händler bewegen Ressourcen. Wo Händler häufig laufen, entstehen Trampelpfade. Die Welt speichert ihr Verhalten.
Die Welt ist dynamisch:
Bäume wachsen nach
Fische regenerieren sich
Felder müssen neu bestellt werden
Militärisch stehen Miliz, Schwertkämpfer, Bogenschützen, Reiterei und Belagerungseinheiten bereit. Mauern, Tore, Brücken, Häfen und Markthandel erweitern die taktischen Möglichkeiten.
Ein KI-Gegner baut parallel eine eigene Wirtschaft auf und greift an. Keine statische Skript-Logik, sondern ein System mit eigenem Ressourcenfluss.
Dazu kommen:
Autosave
Minimap
Einheitengruppen
Prozeduraler Sound über die Web Audio API
Hintergrundmusik mit Suno generiert
Alles ohne externe Abhängigkeiten. Keine Engine. Keine Bibliotheken. Keine Toolchain.
Warum das spannend ist
Früher hätte ein solches Projekt Monate oder Jahre bedeutet. Setup, Tooling, Architektur, Iterationen.
Heute verschiebt sich die Grenze zwischen Idee und Umsetzung spürbar. Nicht, weil Code trivial geworden ist. Sondern weil sich die Art der Zusammenarbeit verändert.
Mit KI-Unterstützung entsteht Software im Dialog. Man beschreibt ein System, bekommt eine erste Version, refaktoriert gemeinsam, diskutiert Datenstrukturen, optimiert Logik und erweitert Mechaniken. Iteration wird extrem schnell.
Dieses Spiel ist kein Produkt. Kein Monetarisierungsmodell. Kein Jira-Board.
Es ist ein Experiment.
Ein Experiment, wie weit man mit klarer Architektur, strukturiertem Denken und KI-Unterstützung kommen kann, wenn man sich einfach einen Tag Zeit nimmt und baut.
Die Idee, Entwickler könnten bald ersetzt werden, taucht in regelmäßigen Wellen auf. In den 60er Jahren hieß es, höhere Programmiersprachen würden das Problem lösen. Später sollten CASE-Tools, dann No-Code-Plattformen, dann Outsourcing den Bedarf an spezialisierten Entwicklern drastisch senken. Jedes Mal wurde es einfacher, Software zu produzieren. Und jedes Mal verschwand die Komplexität nicht, sie verlagerte sich nur.
Heute trägt diese alte Erzählung ein neues Gewand. Generative KI kann in Sekunden Code erzeugen, Tests schreiben, Refactorings vorschlagen. Gleichzeitig verlieren Junior-Entwickler und Regular-Entwickler spürbar an Marktwert, weil viele klassische Einstiegsaufgaben automatisierbar geworden sind. Und selbst erfahrene Entwickler werden in Deutschland entlassen, häufig aus Kostengründen oder aufgrund strategischer Fehlentscheidungen im Bezug auf KI.
Das wirkt wie ein Widerspruch. Wenn alles automatisiert wird, warum bleiben echte Seniors rar? Warum sind Architekten, die Systeme verstehen, weiterhin so gefragt?
Die Antwort ist unspektakulär, aber entscheidend: Werkzeuge reduzieren Oberflächenarbeit. Sie eliminieren keine Komplexität. Software ist kein Textproblem. Sie ist ein Strukturproblem.
Und genau dort trennt sich gerade der Markt.
Was gerade wirklich an Wert verliert
An Wert verliert vor allem reine Codeproduktion ohne strukturelles Denken.
Ein einfaches Beispiel:
Prompt: „Erstelle mir eine REST API mit Spring Boot für Benutzerverwaltung.“
Das Ergebnis ist meist funktional:
Controller
Service
Repository
CRUD-Endpunkte
Alles läuft. Tests vielleicht auch.
Aber was fehlt oft?
Keine klare Trennung zwischen Domain und Infrastruktur
Geschäftslogik im Controller
Direktzugriff auf JPA-Entities im API-Layer
Keine expliziten Ports
Keine durchdachte Fehlerstrategie
Kurzfristig sieht das produktiv aus. Langfristig entsteht Kopplung, die jede Erweiterung teuer macht. Auch mit KI. Wenn ein Junior nur lernt, so etwas zu generieren und zu akzeptieren, wird er austauschbar. Die KI liefert denselben Output.
Was stattdessen wertvoll wird
Wertvoll wird die Fähigkeit, Systeme zu formen.
1. Ports und Adapter wirklich verstehen
Nehmen wir dasselbe Beispiel, aber strukturiert gedacht.
Statt direkt auf JPA im Controller zuzugreifen, wird eine Domain-Schicht gebaut:
@Repository
class JpaUserRepository implements UserRepository {
// mapping between JPA entity and domain
}
Der Controller spricht nicht mit JPA, sondern mit einem Use Case:
public class CreateUserUseCase {
private final UserRepository repository;
public void execute(CreateUserCommand command) {
User user = User.create(command);
repository.save(user);
}
}
Plötzlich entsteht:
Entkopplung
Testbarkeit ohne Datenbank
Austauschbarkeit der Persistenz
Klar definierte Verantwortlichkeiten
Eine KI kann diesen Code erzeugen. Aber nur, wenn jemand versteht, warum er so aussehen sollte.
2. Dependency Inversion bewusst einsetzen
Viele KI-generierte Lösungen hängen direkt an Frameworks:
@Service
public class PaymentService {
@Autowired
private StripeClient stripeClient;
}
Das sieht harmlos aus, koppelt aber die Fachlogik direkt an Stripe. Sauber gedacht würde man stattdessen ein Port definieren und dann eine Stripe-Adapter.
public interface PaymentGateway {
PaymentResult charge(Money amount);
}
class StripePaymentGateway implements PaymentGateway {
// Stripe specific logic
}
Jetzt hängt die Domain nicht mehr an Stripe. Sie hängt an einer Abstraktion. Das ist kein akademisches Detail. Das ist strategische Beweglichkeit.
3. Modularisierung statt Ordnerstruktur
Viele Projekte nennen sich „modular“, sind aber nur nach Technik sortiert:
controller
service
repository
dto
Echte Modularisierung schneidet nach fachlichen Grenzen:
billing
user-management
reporting
notification
Jedes Modul hat:
eigene Use Cases
eigene Ports
eigene Adapter
Abhängigkeiten zeigen nur in eine Richtung. Das erfordert Denken. Und genau das wird gerade wertvoll.
4. KI richtig einsetzen
KI ist kein Ersatz für Architektur. Sie ist ein Beschleuniger. Statt zu sagen: „Schreib mir einen Service.“ Sagt man besser: „Erzeuge eine Clean-Architecture-Struktur mit klar getrenntem Domain-Kern, Ports für Persistenz und Messaging, Adapter im Infrastruktur-Layer, keine Framework-Abhängigkeiten im Domain-Modul.“ Der Unterschied im Output ist dramatisch. KI verstärkt Präzision. Sie verstärkt aber auch Unschärfe. Wer nur delegiert, produziert strukturelle Schulden in Rekordgeschwindigkeit.
Was Junioren konkret tun sollten
Architektur lesen, nicht nur Tutorials konsumieren Clean Architecture, Hexagonal Architecture, modulare Monolithen wirklich durcharbeiten.
Refactoring üben Einen schlecht strukturierten Code bewusst in saubere Module überführen.
Tests ernst nehmen Nicht nur happy path, sondern Verhalten absichern.
Domänenmodelle bauen Geschäftslogik explizit modellieren statt in Services zu verteilen.
KI als Sparringspartner nutzen Code generieren lassen, dann kritisch zerlegen:
Der Markt selektiert gerade brutal, aber klar. Reiner Output verliert an Wert. Systemdenken gewinnt an Wert. Junioren, die sich jetzt in saubere Abhängigkeitsstrukturen, Modularisierung und Architektur vertiefen, entwickeln sich schneller in Richtung Senior als es früher möglich war. Nicht über Jahre von Tickets, sondern über bewusstes Strukturtraining. KI nimmt einfache Arbeit weg. Sie zwingt aber auch dazu, das Wesentliche zu lernen.
Und das Wesentliche war noch nie das Tippen von Code. Es war immer das Entwerfen von Systemen.
Software ist erst dann etwas wert, wenn sie benutzt wird. Alles davor ist Vorbereitung.
Dieser Satz klingt banal, trifft aber einen Nerv, weil ein Großteil dessen, was im Alltag als gute Softwareentwicklung gilt, genau an dieser Stelle endet. Code existiert, Konzepte sind sauber, Architekturen durchdacht, Tests fast vollständig. Und trotzdem bleibt das Ergebnis seltsam folgenlos. Es funktioniert, aber es wirkt nicht.
Entwickeln bewegt sich im Möglichkeitsraum. Solange entwickelt wird, ist alles noch verhandelbar. Abstraktionen lassen sich verbessern, Entscheidungen vertagen, Alternativen offenhalten. Entwickeln ist ein Zustand, in dem man intelligent sein darf, ohne sich festzulegen. Genau deshalb fühlt er sich produktiv an, auch wenn am Ende noch nichts nutzbar ist.
Liefern ist das Gegenteil. Liefern zwingt zur Festlegung. Es verlangt, Entscheidungen zu schließen, Unschärfen zu akzeptieren und Verantwortung für einen Zustand zu übernehmen, der nun real ist. Ab diesem Moment gehört Software nicht mehr dem Entwickler, sondern den Nutzern, dem Betrieb, dem System. Fehler werden sichtbar, Annahmen überprüfbar, Qualität messbar. Liefern macht Software angreifbar.
Der bekannte 80:20-Grundsatz ist hier kein Methodenwissen, sondern ein Charaktertest. Fast jeder Entwickler kennt ihn, viele können ihn erklären, aber nur wenige setzen ihn um, wenn es darauf ankommt. Denn 80:20 heißt nicht, schlampig zu arbeiten, sondern bewusst auf die letzten zwanzig Prozent Perfektion zu verzichten, um achtzig Prozent Wirkung zu erreichen. Das erfordert keine zusätzliche Technik, sondern Entscheidungskraft.
Typisch ist der Zustand des formalen Unfertigseins. Funktional ist alles vorhanden, aber Tests sind noch nicht ganz rund, Dokumentation existiert nur implizit, Konfiguration liegt im Kopf einzelner Personen, Betriebsannahmen sind nicht explizit gemacht. Das System läuft, aber nur, solange die richtigen Menschen verfügbar sind. Es ist gebaut, aber nicht übergeben.
Liefern bedeutet, diesen Zustand bewusst zu verlassen. Es heißt, Dinge so abzuschließen, dass andere sie nutzen können, ohne Rückfragen, ohne implizites Wissen, ohne Abhängigkeit vom Erbauer. Fertig heißt nicht perfekt, sondern stabil genug, um realen Betrieb auszuhalten. Alles Weitere entsteht aus Nutzung, nicht aus weiterer Theorie.
Gerade sehr gute Entwickler scheitern an dieser Schwelle. Wer viel weiß, sieht viele Risiken, viele Alternativen und viele offene Enden. Ohne die Fähigkeit, bewusst zu stoppen, wird Wissen zur Ausrede, nicht zu liefern. Das System bleibt im Entwicklungszustand, elegant, aber folgenlos.
An genau dieser Stelle zeigt sich Seniorität. Nicht im Umfang des Wissens, nicht in der Raffinesse der Lösung, sondern in der Fähigkeit, Verantwortung zu übernehmen. Ein Senior erkennt, wann Entwickeln aufhören muss, damit Liefern beginnen kann. Er akzeptiert, dass reale Nutzung härter, aber ehrlicher ist als jede weitere Optimierung.
Organisationen belohnen diesen Unterschied oft falsch. Technische Brillanz ist sichtbar, Abschluss ist leise. Konzepte beeindrucken, Übergaben fallen erst auf, wenn sie fehlen. So entsteht ein Umfeld, in dem Entwickeln gefeiert wird und Liefern als selbstverständlich gilt, obwohl genau dort der eigentliche Wert entsteht.
Der Unterschied zwischen Entwickeln und Liefern ist deshalb kein Detail und keine Methodendiskussion. Er ist ein Reifegrad. Entwickeln zeigt, was jemand kann. Liefern zeigt, wofür jemand bereit ist einzustehen. Erst wenn beides zusammenkommt, entsteht Software, die nicht nur gebaut wurde, sondern wirklich existiert.
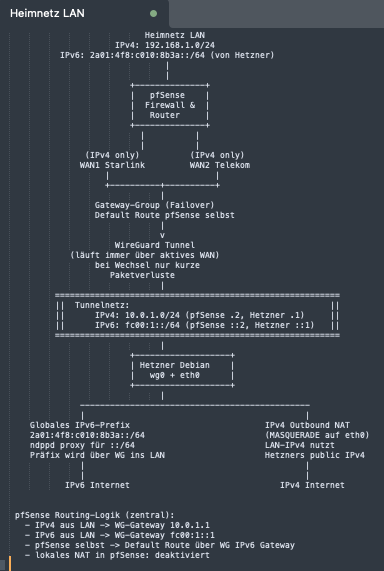
Multi-WAN ohne Prefix-Chaos mit PFSENSE und HETZNER
Sobald im Heimnetz zwei verschiedene Internetanschlüsse zusammenkommen, entsteht ein Problem, das sich bei IPv4 elegant durch NAT versteckt, bei IPv6 aber offen zutage tritt. Beide Leitungen liefern unterschiedliche globale Präfixe, die jeweils an das jeweilige Provider-Netz gebunden sind. Ein Gerät, das ein IPv6-Paket über die erste Leitung verschickt, muss den Rückverkehr zwingend über genau diese Leitung empfangen. Diese strikte Bindung an den Ursprungs-Prefix gehört zum Kernprinzip von IPv6, das ohne NAT auskommt und den globalen Routingpfad offenlegt.
Sobald jedoch zwei WANs mit zwei verschiedenen Präfixen gleichzeitig aktiv sind, beginnt sich das Netz selbst zu widersprechen. Ein Client bekommt mehrere globale IPv6-Adressen aus beiden Präfixen, und die pfSense kann zwar entscheiden, welcher Upstream aktuell aktiv ist, aber sie darf das dazugehörige Präfix nicht dynamisch ersetzen. Die von den Clients verwendeten Adressen bleiben für viele Stunden gültig. Ein schnelles Wegschalten ist im IPv6-Standard nicht vorgesehen, da Router Advertisements große Zeitfenster haben und Adressen nicht spontan wegfallen sollen. Damit verliert der Rückweg den Bezug zur Quelle, und Verbindungen brechen ab, sobald die pfSense bei Ausfall eines WANs auf den anderen umschaltet.
Diese Situation lässt sich nicht mit Routenregeln, Gateway-Gruppen oder Failover-Mechanismen umgehen, da das Problem auf der Adresslogik selbst beruht. IPv6 verlangt für stabile Rückwege einen klaren, konsistenten Präfix-Ursprung. Genau deshalb scheitert klassisches Multi-WAN mit wechselnden Präfixen, während IPv4 dank NAT unbeeindruckt bleibt und einfach die Quelladresse umschreibt, sodass der Rückweg immer passt.
Die Lösung besteht darin, sich einen stabilen, unabhängigen Punkt zu schaffen, von dem der globale IPv6-Präfix kommt. Ein kleiner Hetzner-Server übernimmt diese Rolle. Er trägt das IPv6-Präfix dauerhaft und übersetzt gleichzeitig IPv4. Die pfSense verbindet sich nur noch per WireGuard-Tunnel mit ihm, und beide lokalen WANs dienen lediglich als Transportweg. Damit wird das gesamte Netz stabil, unabhängig davon, welche Leitung gerade aktiv ist.
1. Hetzner-Server vorbereiten
Debian 13 Mini, WireGuard und Prefix-Weitergabe
Der Server bildet den ruhenden Pol in der Architektur. Er hält die IPv6-Adresszone bereit und sorgt dafür, dass IPv4 sauber ins Internet übersetzt wird, unabhängig davon, welche Leitung zuhause aktiv ist.
Das interne Tunnelnetz (10.0.1.0/24 und fc00:1::/64) verbindet den Server klar mit der pfSense. Zusätzlich wird das globale IPv6-/64 dem Peer bekannt gemacht.
ND-Proxy einrichten
Da Hetzner nur eine /128 am Interface vergibt, übernimmt ndppd die Antwort auf Neighbor-Discovery-Anfragen für das gesamte Präfix:
Der Server hat so eine klare, feste Adresse, während das Präfix selbst durch ndppd verwaltet wird.
IPv4-Masquerading aktivieren
Damit das gesamte IPv4-LAN über den Tunnel sauber ins Internet gelangt, wird NAT in Richtung Hetzner-Interface aktiviert:
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Die Regel bleibt dauerhaft aktiv und sorgt dafür, dass der Rückverkehr immer beim Server endet, unabhängig vom Zustand der heimischen WANs.
Damit ist der Server fertig.
2. pfSense vorbereiten
Zwei WANs, ein Tunnel, kein eigenes NAT mehr
Die pfSense verwendet ihre beiden WANs nur noch dazu, den Tunnel aufrechtzuerhalten. Der eigentliche Internetverkehr wird durch WireGuard transportiert. Alle Schritte beziehen sich auf das Menü der pfSense.
WAN-Konfiguration
Richtet die beiden WAN Schnittstellen ein. Bei mir WAN1 WAN2. Lasst die IPv6 Config einfach leer. Nutzen wir nicht. Dann auf:
Ort: System → Routing → Gateways
Beide WAN-Gateways werden auf IPv4 gestellt. Der Haken „Kill states when gateway is down“ sorgt dafür, dass Sessions beim Umschalten direkt sauber neu aufgebaut werden.
Gateway-Gruppe
Ort: System → Routing → Gateway Groups
Eine Gruppe mit beiden WANs, z. B. WAN1 als Tier 1 und WAN2 als Tier 2. Diese Gruppe wird später die Default-Route der pfSense. Damit springt der Tunnel automatisch auf die gerade funktionierende Leitung.
NAT deaktivieren
Ort: Firewall → NAT → Outbound
Outbound-Modus auf „Disabled“ setzen. Die pfSense übernimmt kein NAT mehr, da das Hetzner-System diese Rolle zuverlässig übernimmt.
3. WireGuard auf pfSense
Tunnel aufbauen und als neues Gateway nutzen
Erst unter Packages “Wireguard” installieren.
Tunnel konfigurieren
Ort: VPN → WireGuard → Tunnels
Ein neues Tunnelinterface anlegen, z. B. WG-Hetzner, mit diesen Adressen:
10.0.1.2/24
fc00:1::2/64
Das Gegenstück zeigt auf die externe IPv4 vom Hetzner-Server.
WireGuard-Interface erzeugen
Ort: Interfaces → Assignments
Das WG-Interface hinzufügen und aktivieren. IPs eintragen. Speichern. Gateways hinzufügen.
Gateways definieren
Ort: System → Routing → Gateways
IPv4-Gateway: 10.0.1.1
IPv6-Gateway: fc00:1::1
Beide auf „Unmonitored“ stellen, damit pfSense sie nicht fälschlich als offline erkennt.
Default-Route auf den Tunnel legen
Ort: System → Routing → Routes
Die pfSense selbst nutzt das IPv6-Gateway des Tunnels als Default-Route. Damit läuft der gesamte Systemverkehr (Updates, DNS, Checks) über Hetzner.
4. LAN-Traffic durch den Tunnel schicken
IPv4 über den Tunnel
Ort: Firewall → Rules → LAN
Die bestehende IPv4-Regel auf das Gateway 10.0.1.1 umstellen. Damit geht sämtlicher IPv4-Verkehr über WireGuard.
IPv6 über den Tunnel
In der IPv6-Regel das Gateway fc00:1::1 auswählen.
Damit ist klar, dass das globale IPv6-Präfix über Hetzner zurückgeführt wird.
5. WireGuard-Interface erlauben
Ort: Firewall → Rules → WG-Interface
Eine einfache „Any to Any“-Regel erzeugen, da der gesamte Verkehr durch dieses Interface läuft.
6. IPv6 im LAN verteilen
Ort: Interfaces → LAN → Static IPv6 und Ort: Services → Router Advertisements
Das globale Hetzner-Präfix im LAN hinterlegen, z. B.:
2a01:4f8:c010:8b3a::2/64
Router Advertisements aktivieren, damit Clients sofort gültige IPv6-Adressen erhalten. In diesem Fall “Assisted” auswählen. IPv4 bleibt klassisch über DHCP, z. B. 192.168.1.1.
7. Ergebnis genießen
Die Kombination aus Tunnel, statischem IPv6-Präfix und zentralem IPv4-NAT ergibt ein äußerst stabiles Netz. Die beiden heimischen WANs dienen nur noch dazu, den Tunnel erreichbar zu halten. Da WireGuard bei Leitungswechseln kaum empfindlich ist, entstehen meist nur wenige verlorene Pakete, bevor der Verkehr transparent weiterläuft. Da Absender und Ziel gleich bleiben, verliert man in der Regel keine Verbindung. IPv6 bleibt dauerhaft gültig und verliert nie sein Präfix. IPv4 ist dank Hetzner-NAT unabhängig von lokalen Providerwechseln.
Damit entsteht ein kleines, robustes Hybridmodell, das die Vorteile eines Rechenzentrums mit einem dynamischen Heimnetz kombiniert.
Edit: Und wer jetzt keine Pakete durchbekommt, hat vermutlich das Offensichtliche vergessen. Auf dem Debian-Server muss natürlich IP-Forwarding aktiviert werden, sonst bleibt alles schön im Kernel stecken.
„The trouble with the world is that the stupid are cocksure and the intelligent are full of doubt.“
— Bertrand Russell
Der Punkt, an dem „intelligent“ nicht gleich „vernünftig“ ist
Bertrand Russell beschreibt die aktuelle Lage der künstlichen Intelligenz hervorragend. Während viele Systeme mit erschütternder Selbstsicherheit handeln, fehlt ihnen genau das, was Intelligenz eigentlich ausmacht: Zweifel.
Generative Modelle wie GPT, Claude oder Gemini beeindrucken durch sprachliche Eleganz und scheinbare Rationalität. Doch sie sind nicht intelligent, sie approximieren. Mit dem Message Context Protocol (MCP), das diesen Modellen erlaubt, externe Funktionen auszuführen, etwa Mails zu verschicken, Daten zu verändern oder Tickets anzulegen, verleihen wir ihnen Handlungsspielräume, die sie weder verstehen noch beherrschen.
Damit überschreiten wir die Grenze zwischen kommunikativer und operativer Intelligenz. Und es entsteht eine neue Klasse von Risiken, die weit über technische Fehler hinausgeht.
Die falsche Gleichung: Sprachmodell = Intelligenz
Große Sprachmodelle (LLMs) beruhen nicht auf Denken, sondern auf fragmentierter Statistik. Mathematisch approximieren sie die bedingte Wahrscheinlichkeit, dass ein bestimmtes Token (Wortfragment) nach einer gegebenen Sequenz folgt. Diese Annäherung kann katastrophal falsch sein und das in unerwarteten Momenten.
Diese Wahrscheinlichkeiten werden in Milliarden Parametern abgebildet und durch Aktivierungsfunktionen wie ReLU oder GeLU in numerische Näherungen („Approximationswerte“) transformiert. Das Ergebnis ist kein echtes Wissen, sondern eine angenährte Sprachwahrscheinlichkeit. Die Lernfunktion der Modelle ist probabilistisch. Das, was wir am Ende sehen, ist eine geglättete Konfidenz über sprachliche Plausibilität, nicht über Wahrheit oder logische Kausalität.
Kurz gesagt: GenAI erzeugt Text, der richtig klingt, nicht Text, der richtig ist.
Das Seepferdchen-Emoji, die Frage, die das Chaos offenbarte
Das vermeintlich harmlose „Seepferdchen-Emoji“ ist zu einem Sinnbild der KI-Instabilität geworden.
Fragt man ein Sprachmodell danach, antwortet es überzeugt, „Ja, das gibt es“, korrigiert sich, halluziniert, und fällt in eine fast unendliche Schleife, die mit einer vernünftigen Antwort absolut nichts mehr zu tun hat.
Dieser Fehler ist kein kurioses Detail, sondern ein technisches Symptom: Er zeigt, dass Modelle keine semantische Stabilität besitzen. Wenn selbst triviale Fragen unvorhersehbare Reaktionen auslösen, sind agentische Anwendungen, also solche, die handeln dürfen, potenziell brandgefährlich. Praktisch jede Frage, egal wie vorsichtig formuliert, könnte eine Seepferdchen-Emoji-Frage sein.
MCP, Wenn Sprache plötzlich Macht bekommt
Mit dem Message Context Protocol (MCP) erhalten Sprachmodelle die Fähigkeit, externe Funktionen auszuführen. Was früher ein rein textbasiertes Chat-System war, kann nun real agieren: Jira-Tickets erstellen, Systeme konfigurieren, E-Mails senden, Datenbanken abfragen.
Das MCP ist im Kern ein Kommunikationsprotokoll, das Kontext und Befehle standardisiert an externe Schnittstellen weitergibt. Damit wird aus einer passiven Text-KI ein aktives System, das reale Prozesse anstößt. Diesen Vorgang nennen wir aktuell Agentic AI. Wir unterstellen den Agenten Intelligenz, allerdings werden Handlungen nur generiert, nicht gedacht.
Genau diese Verbindung ist heikel. Denn die zugrundeliegende KI, ein stochastisches Sprachmodell, weiß nicht, was sie tut. Sie erkennt keine Grenzen zwischen plausibler und gefährlicher Aktion.
Ein harmloser Befehl wie „Erstelle bitte ein Ticket für alle betroffenen Projekte“ kann, je nach Implementierung, eine Flut von 100.000 Vorgängen erzeugen, ein ungewollter Denial-of-Service durch Sprachwahrscheinlichkeit.
Die Ursache: Das Modell interpretiert Sprache probabilistisch, nicht kausal. Es weiß nicht, was „alle Projekte“ bedeutet. Es weiß nur, dass diese Phrase oft mit einer Massenerstellung in Trainingsdaten korrelierte.
Die Illusion der Intention
Durch MCP entsteht eine gefährliche Täuschung: Ein Sprachmodell, das handeln kann, wirkt rational, ist es aber nicht.
Es hat keine Ziele, kein Bewusstsein, keine Vorstellung von Risiko. Es generiert Text, der über MCP zu einer echten Aktion wird. Was dabei fehlt, ist ein Verständnis von Ursache und Wirkung.
Das bedeutet: Eine vernünftige Frage kann denselben Effekt haben wie die Seepferdchen-Frage, eine scheinbar harmlose Eingabe, die in einem komplexen System katastrophale Kettenreaktionen auslöst.
Human in the Loop, ein unzureichendes Sicherheitsversprechen
„Wir setzen einfach einen Menschen in die Schleife.“
Human-in-the-Loop (HITL) oder Human-on-the-Loop (HOTL) beschreiben menschliche Eingriffsmechanismen in KI-Systeme. Der Begriff „Human“ ist dabei viel zu allgemein. Ein beliebiger Mitarbeiter ist nicht automatisch qualifiziert, KI-Fehler zu erkennen oder ihre Risiken zu verstehen.
Deshalb müsste der AI-Act korrekterweise von Expert-in-the-Loop oder Expert-on-the-Loop sprechen.
Denn: Ein Sekretär darf keine automatisierten Buchungen freigeben, ein Sachbearbeiter kann keine algorithmischen Biases bewerten, und ein Entwickler ohne Fachkontext erkennt nicht, wann die KI einen regulatorischen Grenzfall überschreitet.
Fachkompetenz kann Fehler erkennen, nicht bloße Anwesenheit eines Menschen.
Und selbst darüber hinaus: Ein Entwickler kann nicht notwendigerweise schnell genug eingreifen, wenn sich ein Cursor irrt und beginnt, kritische Daten zu löschen. Zwischen Erkennen und Handeln vergeht Zeit, in einem autonomen System kann diese Verzögerung bereits ausreichen, um irreversiblen Schaden anzurichten.
Die Gefahr der Abstumpfung
Je zuverlässiger ein System wird, desto schwächer wird seine menschliche Kontrolle.
Der Effekt ist psychologisch belegt: Autofahrer mit aktivem Autopiloten reagieren deutlich langsamer in Notfällen. Der Grund: Der Mensch gewöhnt sich an Sicherheit, und verliert die Wachsamkeit.
In der KI gilt dasselbe Prinzip: Ein Buchhalter, der täglich 500 automatisch vorgeschlagene Buchungen bestätigt, prüft irgendwann nicht mehr kritisch. Wenn 999 Vorschläge korrekt sind, übersieht er den einen, der den Jahresabschluss ruiniert.
Je besser das System, desto größer das Risiko der menschlichen Abstumpfung. Das bedeutet man braucht größere Kontrollsysteme. Dinge, die die Aufmerksamkeit des kontrollierenden Experten on/in the Loop lenken.
Anomalieerkennung, also Systeme, die gezielt Abweichungen von erwarteten Mustern hervorheben, kann hier eine wirksame Gegenmaßnahme sein, nicht als Ersatz, sondern als Rückkopplung, die den Menschen im Loop wieder wach macht.
Risikoanalyse Ende-zu-Ende, nicht nur am Modell
Fehlerszenarien dürfen nicht nur auf Modell- oder Prompt-Ebene bewertet werden. Die entscheidende Frage lautet: Was ist der reale Schaden, wenn etwas schiefläuft?
Beispiel
Mögliche Folge
Möglicher Schaden
Bot legt 100.000 Jira-Tickets an
Serverlast, Ausfallzeiten, Datenchaos
Wirtschaftlich hoch, reputativ kritisch
Falsche Buchung durch KI
Bilanzfehler, steuerliche Nachwirkungen
Potenziell juristisch relevant
Bot löscht falsche Datensätze
Verlust von Audit-Trails, Compliance-Verstöße
Revisionsrisiko, Bußgelder
Diese Betrachtung zeigt: Die „Intelligenz“ des Modells ist irrelevant, wenn die Auswirkungen eines Fehlers nicht kontrollierbar sind.
Man stelle sich die Bild-Schlagzeile vor, die erscheinen würde, wenn der Bot aufgrund einer Seepferdchen-Emoji-Frage seinen Handlungsspielraum ausschöpft und dabei eskaliert.
Wenn diese Schlagzeile nach „Systemfehler in Chatbot-KI schickt Krankenwagen zur falschen Adresse“ oder „KI löscht versehentlich Kundenkonten – Schaden in Milliardenhöhe“ klingt, ist das Risiko real, unabhängig davon, wie fortschrittlich das Modell ist und wie durchdacht der Prompt war.
Wirtschaftliche Realität, wenn die Kosten explodieren
Neben dem Risiko ist auch die Wirtschaftlichkeit ein limitierender Faktor. Jede GenAI-Anfrage verursacht Rechenkosten, GPU-Zeit, Energie, API-Tokens.
Viele Projekte rechnen sich nicht. Der ROI verschwindet, sobald man Skalierung, Monitoring und menschliche Aufsicht einbezieht. Eine „smarte“ Automatisierung wird schnell teurer als manuelle Arbeit, besonders, wenn sie regelmäßig korrigiert werden muss.
Damit ist GenAI oft ökonomisch untragbar, wenn sie über reine Textgenerierung hinausgeht.
Der Anti-KI-Hype als Gefahr
Diese Diskrepanz zwischen Kosten, Risiko und tatsächlichem Nutzen befeuert die sogenannte AI-Bubble. Wenn Unternehmen erkennen, dass viele Projekte weder stabil noch rentabel sind, folgt die Ernüchterung.
Das Risiko: eine Gegenbewegung, eine „Anti-AI-Welle“. Plötzlich wird alles, was nach KI klingt, als Gefahr wahrgenommen, regulatorisch, gesellschaftlich, finanziell.
Das wäre fatal. Denn nicht die Technologie ist schuld, sondern ihr unkritischer Einsatz.
Wege zur Reife, fünf Prinzipien verantwortungsvoller KI
Expertise statt Symbolik: Ein „Human“ genügt nicht, Fachwissen ist Pflicht.
Funktionale Begrenzung: KI darf nur dort handeln, wo Konsequenzen reversibel sind.
Ende-zu-Ende-Risikoprüfung: Der Schaden zählt, nicht die Präzision des Modells.
Wirtschaftliche Vernunft: Kosten und Nutzen ehrlich bilanzieren, vor dem Rollout.
Transparente Aufklärung: Klar kommunizieren: GenAI approximiert Sprache, sie denkt nicht.
Verantwortung ist die eigentliche Intelligenz
Die gegenwärtige KI-Blase entsteht nicht, weil Modelle zu schlecht sind, sondern weil wir ihnen zu viel zutrauen.
Wir geben Systemen Macht, die nicht verstehen, was sie tun. Wir interpretieren statistische Sprache als logisches Denken. Und wir öffnen ihnen über Protokolle wie MCP Tore zu einer Welt, deren Risiken sie nicht begreifen können.
Die Zukunft von KI entscheidet sich nicht an der Größe der Modelle, sondern an der Reife ihrer Nutzer. Die wirtschaftliche Erfolg einer KI wird also nicht durch Anzahl der Parameter bestimmt, sondern durch Prinzipien.
Wer Verantwortung vor Geschwindigkeit stellt, bewahrt Innovation vor ihrem eigenen Untergang. Und betrachtet man es nüchtern, ist Europa mit dem AI-Act vielleicht besser vorbereitet als die USA.
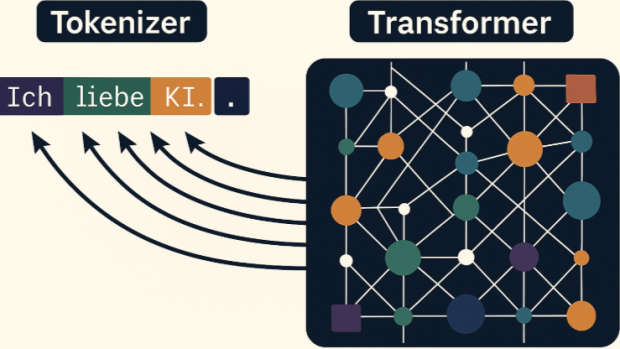
In Diskussionen über Sprachmodelle fällt das Wort „Transformer“ beinahe reflexhaft. Man spricht über Attention, über Layer, über Billionen Parameter. Doch das eigentliche Genie liegt nicht in der Architektur, sondern davor: im Tokenizer.
Denn der Transformer kann nur berechnen, was der Tokenizer zuvor definiert hat. Er denkt nicht in Wörtern, nicht in Sätzen, nicht in Konzepten, sondern in numerisch kodierten Fragmenten sprachlicher Realität.
Der Tokenizer ist die epistemische Linse, durch die eine Maschine die Welt überhaupt erst sehen kann.
Von Zeichen zu Bedeutung
Der Tokenizer übersetzt Sprache, Code oder Zahlen in diskrete Einheiten – Tokens. Diese Tokens sind keine Wörter, sondern Bytefolgen, deren Segmentierung aus Häufigkeit und Kontextinformation gelernt wurde. Ein einfacher Satz, wie:
Das mag trivial wirken, ist aber die Grundlage maschinellen Verstehens. Denn derselbe Mechanismus funktioniert ebenso für HTML, Programmcode oder mathematische Ausdrücke:
Das Modell sieht überall nur Sequenzen von Token-IDs, eine universelle Sprache aus Zahlen, die gleichermaßen natürliche Sprache, Symbolik und Syntax kodiert. Das ist die eigentliche Genialität: nicht der Transformer, sondern die Quantisierung der Sprache selbst.
Man beachte, dass die Leerzeichen teilweise dem Token zugeordnet werden. Außer am Satzanfang und am Satzende. Trotzdem, die symbolische Bedeutung der einzelnen Zeichen geht verloren. Daher kann GPT auch nicht zählen, wie viele r das Wort Strawberry hat. Außer, man trickst mit dem Tokenizer ein wenig.
Warum GPT nicht wirklich rechnet
Die Tokenisierung hat allerdings auch ihre Schattenseiten. Zahlen sind keine kontinuierlichen Größen, sondern diskrete Symbole. „42“ ist ein einziges Token, es steht nicht in einem numerischen Verhältnis zu „41“ oder „43“. Das Modell kann also keine numerischen Operationen durchführen, weil die numerische Struktur bereits beim Tokenizing zerstört wird. Es müsste diese Beziehung erst wieder lernen. In symbolischen Systemen wäre diese Beziehung explizit hinterlegt, im neuronalen System muss sie emergent aus Korrelationen rekonstruiert werden. Größere Zahlen werden oft in 3er-Gruppen von Ziffern zerlegt. Eine kluge Darstellung für Sprache, eine schlechte Darstellung für Mathematik. Das BPE-Verfahren behandelt numerische Blöcke nicht als kontinuierliche Werte, sondern als häufige Zeichenmuster, wodurch jede arithmetische Struktur verloren geht.
Das erklärt, warum GPT häufig bei Rechenaufgaben scheitert: Es sieht keine Zahlen, sondern Wörter mit Zahlenbedeutung. „42“ ist für das Modell ähnlich wie „Katze“, ein Token mit Kontext, nicht mit Arithmetik.
Interessanterweise ist dieses Defizit nicht rein maschinell. Auch Menschen denken über Zahlen tokenisiert. „42“ ist kulturell aufgeladen, als Meme, als Symbol, als literarische Konstante. Andere Sprachen illustrieren diese Segmentierung besonders deutlich: Das französische „quatre-vingt-dix“ (wörtlich „viermal zwanzig und zehn“) oder das japanische „hyaku“ (百 für 100) zeigen, dass auch menschliches Zahlverständnis nicht linear, sondern linguistisch kodiert ist.
Wir denken über Zahlen, wie der Tokenizer sie sieht: als sprachliche Einheiten, nicht als Mengen.
Von Wahrscheinlichkeiten zu Fragmenten
Das Training eines Sprachmodells basiert auf der bedingten Verteilung
P(ti ∣t1 , t2, …, ti−1)
der Wahrscheinlichkeit, dass ein bestimmtes Token ti als Nächstes folgt. Doch diese Wahrscheinlichkeit existiert im Modell nicht als analytische Funktion. Sie wird approximiert durch eine Vielzahl gewichteter Matrizen, deren Aktivierungen über Gradientendeszente so lange angepasst werden, bis die Differenz zwischen Vorhersage und tatsächlichem nächsten Token minimiert ist.
Was bleibt, ist kein probabilistischer Raum, sondern ein deterministisches Feld nicht linearer Approximationen. ReLUs eliminieren negative Aktivierungen und brechen damit Symmetrien. Damit wird jede probabilistische Interpretation systematisch zerstört, was bleibt, ist ein deterministisches Aktivierungsmuster, das sich nur noch statistisch deuten lässt. Dropout deaktiviert zufällig Neuronen und fragmentiert den Signalfluss.
Die oft zitierte Formel P(W∣C), die Wahrscheinlichkeit des nächsten Wortes W im Kontext C, existiert im trainierten Modell nicht mehr explizit. Sie ist lediglich die Zielfunktion des Lernprozesses, deren Spur sich in der Topologie der Gewichtsmatrizen verliert.
Das Ergebnis ist ein fragmentierter Aktivierungsraum, in dem Bedeutung als stabiler Attraktor entsteht, nicht als Wahrscheinlichkeitsverteilung. Das Modell konstruiert Kohärenz ohne Wahrheitszugang, es berechnet Konsistenz, nicht Realität.
Wie der Tokenizer Bedeutung ermöglicht
Der Transformer selbst ist architektonisch blind. Er multipliziert Matrizen, aggregiert Gewichte, verteilt Aufmerksamkeit. Aber was er tatsächlich „sieht“, hängt vollständig von der Tokenisierung ab.
Wenn der Tokenizer entscheidet, dass „magisch“ in „mag“ und „isch“ zerlegt wird, dann entsteht Bedeutung auf der Ebene dieser Fragmente, nicht des Wortes. Das Embedding jeder dieser Subtokens wird im Training über Millionen Kontexte hinweg angepasst. Ihre semantische Nähe ergibt sich aus der Korrelation ihrer Aktivierungen mit anderen Tokens.
„Hund“ ist kein Symbol, sondern eine Abfolge von Tokens wie [“H”, “und”], deren Koaktivierungen sich mit anderen Tier-bezogenen Tokens stabilisieren. „Schraubenzieher“ besteht aus [“Sch”, “rau”, “ben”, “zie”, “her”], deren Aktivierungspfade in Clustern erscheinen, die mit Werkzeugbegriffen korrelieren.
Semantik entsteht nicht auf der Wortebene, sondern als mehrschichtige Interferenz im hochdimensionalen Embedding-Raum. Der Tokenizer definiert die Atome, aus denen diese Semantik gebaut wird.
Der eigentliche Durchbruch
Der Tokenizer ist damit kein Vorverarbeitungsschritt, sondern das epistemische Fundament der gesamten Sprachintelligenz. Aber auch seine natürliche Grenze.
Er komprimiert die Welt in endlich viele Symbole, deren Dichte und Segmentierung bestimmen, welche Realität das Modell überhaupt lernen kann.
Es gibt Ansätze, die auf der Bedeutung einzelner Zeichen ansetzen. Allerdings haben diese auch einen viel höheren initialen Trainingsaufwand, um die Bedeutung ganzer Wörter zu verstehen.
Ein anderer Tokenizer, ein anderes Weltbild. Ein Tokenizer, der Zahlen nicht segmentiert, erzeugt ein Modell, das nicht rechnen kann. Ein Tokenizer, der Satzzeichen ignoriert, erzeugt ein Modell ohne Syntaxverständnis. Ein Tokenizer, der Zeichen falsch auftrennt, zerstört Semantik, bevor sie entstehen kann. Ein Modell ohne Tokenizer konvergiert aktuell nicht.
Der Transformer wäre dann ein Rechenwerk ohne Sprache, eine lineare Algebra über Rauschen.
Der Tokenizer bildet die Grenzfläche zwischen Sprache und Zahl, zwischen Syntax und Semantik. Seine Effizienz liegt darin, dass er Bedeutung komprimiert, bevor sie überhaupt verstanden wird. Er ist damit nicht nur das technische Fundament der modernen Sprachmodelle, sondern auch ihr erkenntnistheoretischer Rahmen.
Ich dachte, USB-C wäre die Lösung. Ein Stecker für alles: Laptop, Handy, Monitor, Kaffeemaschine – alles über ein Kabel. Dachte ich.
Realität: Ein Kabel lädt nur. Eines überträgt Daten. Eins kann 240 Watt, das nächste schmilzt bei 65. Und das teure Thunderbolt-Kabel? Erkennt dein Monitor nicht. Das U steht für “Universal”, sagen sie. “Unberechenbar”, sag ich.
Jedes Mal, wenn ich ein neues USB-C-Kabel in die Hand nehme, fühle ich mich wie bei einem Team, das denselben Jira-Workflow “standardisiert” nutzt.
Alles sieht gleich aus: Open | In Progress | Done.
Aber wehe, man steckt was rein. Das eine Team nutzt “Done” für “läuft lokal”. Das andere für “wartet auf QA”. Und eines schließt’s ab, wenn die Katze vom Entwickler auf Enter drückt.
Sie nennen es Alignment. Ich ‘Feel Good’-Architektur. Jira ist das USB-C der Projektwelt.
Sieht genormt aus, steckt überall und niemand weiß, was es gerade überträgt. Mal Daten. Mal Strom. Mal Hoffnung.
Montagmorgen, 9:15 Uhr. Der Slack-Channel des Teams steht in Flammen. Drei neue P1-Tickets, ein kritisches System ist ausgefallen, zwei Kunden eskalieren gleichzeitig. Der Product Owner klebt hastig weitere Post-its an das ohnehin schon überfüllte Board, einige davon tragen aus Frust den Aufkleber “P0”. Im Hintergrund sitzen Entwickler vor ihren Bildschirmen, müde, mit dunklen Augenringen, einer tippt genervt ein “🔥🔥🔥” in den Chat.
Wenn alles dringend ist, ist am Ende gar nichts mehr dringend. Das Team rutscht in einen Zustand, in dem es nicht mehr gestaltet, sondern nur noch versucht, das Schlimmste zu verhindern. Aus Priorisierung wird Triage.
Priorisieren, solange das System gesund ist
Viele Teams arbeiten mit drei groben Prioritäten. P1 ist für Aufgaben, die sofort erledigt werden müssen. Jede Verzögerung hätte ernste Folgen. P2 sind Aufgaben mit festen Deadlines, die zwar wichtig sind, aber noch etwas Zeit haben. P3 schließlich sind Themen ohne festen Termin – Dinge, die man angeht, wenn Luft dafür ist.
In einem gesunden Team sorgt diese Einteilung für Ruhe. Man weiß, was zuerst erledigt wird, was geplant werden kann und was warten muss. So entsteht ein stabiler Fluss, und die Arbeit erzeugt spürbaren Nutzen.
Doch dieses System hat eine Grenze. Erst bleiben ein paar P3-Aufgaben liegen, was noch völlig normal ist. Dann geraten P2-Themen ins Rutschen, Deadlines werden geschoben. Spätestens wenn selbst P1-Aufgaben nicht mehr zuverlässig fertig werden, ist klar: Hier wird nicht mehr priorisiert, hier wird triagiert.
Der Ursprung des Begriffs
Der Ausdruck Triage kommt aus der Notfallmedizin. Nach einem schweren Unglück müssen Ärzte in kürzester Zeit entscheiden, wen sie zuerst behandeln. Manche Patienten können warten, andere brauchen sofort Hilfe – und in tragischen Fällen gibt es Menschen, die selbst mit allen verfügbaren Ressourcen kaum eine Überlebenschance hätten.
Im normalen Krankenhausbetrieb würde man auch um diese Patienten kämpfen. Doch wenn die Ressourcen nicht ausreichen, müssen Entscheidungen getroffen werden, die unter normalen Umständen undenkbar wären: Einige Patienten werden gezielt zurückgestellt, um möglichst viele andere retten zu können.
Das Ziel ist nicht Gerechtigkeit, sondern Schadensbegrenzung. So viele Menschen wie möglich sollen überleben, auch wenn das harte Entscheidungen erfordert.
Übertragen auf Softwareentwicklung bedeutet das: Das Team kann nicht mehr alles liefern, was wichtig ist. Es geht nicht mehr um die beste Lösung oder den größten Nutzen, sondern nur noch darum, den größten Schaden abzuwenden.
Wenn Triage zum Alltag wird
Triage in Softwareteams schleicht sich ein. Von außen betrachtet sieht man erst kleine Risse: Deadlines werden gelegentlich verschoben, Aufgaben bleiben länger liegen, die Stimmung kippt leicht ins Hektische. Dann beschleunigt sich der Zerfall.
Plötzlich sind fast alle Tickets P1. Niemand traut sich, “Nein” zu sagen. Entwickler springen von einer Eskalation zur nächsten, ohne je etwas richtig abzuschließen. Wichtige, aber nicht akute Themen wie Architektur, technische Schulden oder Qualitätssicherung verschwinden komplett aus dem Blickfeld. Immer öfter verschieben sich Termine, weil einfach nicht genug Zeit da ist.
Nach außen wirkt das wie permanentes Feuerlöschen. Von innen fühlt es sich schlimmer an: Arbeit verliert ihre Struktur und ihren Sinn.
Die psychologische Seite
Im Normalzustand weiß ein Team, warum es arbeitet. Es sieht Fortschritte, kann den eigenen Beitrag zur Wertschöpfung erkennen. Das motiviert und gibt Orientierung.
Im Triage-Modus verändert sich dieses Gefühl. Plötzlich geht es nur noch darum, Verluste zu begrenzen. Das, was nicht geschafft wird, hinterlässt Schuldgefühle. Das, was geschafft wird, sieht niemand, weil sofort die nächste Eskalation beginnt.
Irgendwann redet niemand mehr über neue Ideen oder Verbesserungen. Stattdessen geht es nur noch darum, wer Schuld trägt. Manche werden zynisch, andere ziehen sich innerlich zurück. Burnout und Fluktuation sind dann keine abstrakten Risiken mehr, sondern die logische Folge.
Mehr Leute, mehr Chaos
Wenn Teams am Limit sind, wird oft reflexartig nach mehr Personal gerufen. Das klingt vernünftig, löst aber selten das eigentliche Problem.
Neue Leute müssen eingearbeitet werden. In dieser Zeit sinkt die Leistung sogar, weil erfahrene Teammitglieder weniger schaffen, während sie die Neuen betreuen. Je größer ein Team wird, desto mehr Zeit geht für Abstimmung und Koordination drauf.
Es ist wie beim Kochen: Ein Hähnchen wird bei 200°C nach ein bis zwei Stunden perfekt. Dreht man den Ofen auf 800°C, ist es nach wenigen Minuten nur noch Kohle. Mit Teams ist es genauso – mehr Hitze bringt nicht zwangsläufig ein besseres Ergebnis, sondern oft nur Chaos.
Wenn ständig nach mehr Leuten gerufen wird, ist das oft ein Symptom. Das eigentliche Problem liegt meist tiefer: fehlender Fokus, zu viele parallele Projekte oder Entscheidungen, die keiner treffen will.
Der Weg aus der Triage
Ein Team kommt nicht allein aus diesem Zustand heraus. Es braucht Führung, die klare Prioritäten setzt und den Mut hat, unpopuläre Entscheidungen zu treffen.
Der erste Schritt: radikal ehrlich sein. Nicht alles kann P1 sein. Man muss akzeptieren, dass manche Themen bewusst verschoben oder sogar gestrichen werden. Machmal muss man ganze Projekte einstampfen. Wo wird tatsächlich Geld verdient, wo nicht? Was brauchen wir wirklich? Teams müssen umgestaltet werden, auch wenn Veränderung immer erstmal weh tut.
Dann gilt es, den Arbeitsfluss zu stabilisieren. Weniger parallel anfangen, mehr abschließen. Langfristige Themen wie Architektur oder technische Schulden dürfen nicht mehr unter den Tisch fallen. Und Führungskräfte müssen lernen, “Nein” zu sagen nicht zu den Menschen, sondern zu den Aufgaben, die das Team überfordern.
Nur so kann das Team wieder gestalten, statt nur noch zu reagieren.
Ein kurzer Ausnahmezustand ist normal
Natürlich gibt es Momente, in denen alles auf einmal zusammenkommt – ein großes Release, ein wichtiger Kunde, ein ungeplanter Ausfall. Kurze Phasen, in denen triagiert wird, sind unvermeidlich und manchmal sogar notwendig. Aber sie müssen die absolute Ausnahme bleiben.
Wenn Triage zur Routine wird, verliert das Team die Kontrolle über seine Arbeit. Dann geht es nicht mehr um Wertschöpfung, sondern nur noch ums Überleben. Und am Ende bleibt statt echter Ergebnisse nur noch ein Gefühl von permanentem Scheitern.